Torch and GPU
A major advantage of Torch is how easy it is to write code that will run either on a CPU or a GPU. Very little extra thought or code is necessary.
The way to use a GPU that seems the industry standard and the one I am most familiar with is via CUDA, which was developed by NVIDIA.
Using a GPU in Torch
Using a GPU in Torch is incredibly easy. Getting set up is simply a matter of requiring the cutorch package and using the CudaTensor type for your tensors.
cutorch = require 'cutorch'
x = torch.CudaTensor(2,2):uniform(-1,1)Now all of the operations that involve x will computed on the GPU.
If you have a tensor that is not a CudaTensor but want to make it one, you can use the cuda() function to return a CudaTensor copy of the original:
x = torch.Tensor(2,2):zero()
xCuda = x:cuda()You can see what type of tensor you have by inspecting it in the console:
th> x 0 0 0 0 [torch.DoubleTensor of size 2x2] th> xCuda 0 0 0 0 [torch.CudaTensor of size 2x2]
You can also convert back to a CPU tensor:
th> y = xCuda:double() th> y 0 0 0 0 [torch.DoubleTensor of size 2x2]
Keep in mind that the parameter matrices of the nn.Module objects also need to be configured for GPU use, as these contain internal tensors for storing parameters, and the forward/backward propagation state.
Lucky for us, these also have cuda() methods:
linearMap = nn.Linear(M,M):cuda()Care needs to be taken, because the types of tensors are incompatible. They cannot be multiplied together or used together for any operation. One must always either initially create a CudaTensor if one is desired, or convert an existing tensor to one.
Also, when you persist data to disk using torch.save(), make sure you first convert it to a DoubleTensor or some other type of CPU tensor, otherwise you will not be able to read in the data on a machine without a GPU.
Similarly, when you read data from disk, you will first need to convert the tensors to CudaTensors before performing GPU computations.
Ambidextrous code
Since one often wants to develop code on a machine that doesn’t have a GPU, and then run full training sessions on a machine with a GPU, it’s important to make the code work easily on both machines.
I usually accomplish this in two ways using a flag, use_cuda, that is set as a command line option:
- Saving a reference to my Tensor constructor choice.
- Using a method to localize data to the GPU (or a no-op if not using the GPU).
When I want to use a Tensor that might possibly be a GPU tensor, I can refer to the Tensor global I configure at setup:
if use_cuda then
Tensor = torch.CudaTensor
else
Tensor = torch.Tensor
endAnd here’s my localize function:
localize = function(thing)
if use_cuda then
return thing:cuda()
end
return thing
endAnd this can be used for anything with a cuda() method:
x = localize(torch.rand(3,3))
map = localize(nn.Linear(M,M))Benchmarking
GPUs are very fast at matrix operations due to the way these can be parallelized among the thousand or more cores on a GPU. But they are slow at copying memory across the memory bus. This means that sometimes a CPU is faster for computation because the memroy copying overhead is not worth the computational gains due to parallelization on the GPU.
Also, one generally needs to load ones whole training data set onto the GPU, which takes much longer than reading it into the machine’s main memory.
I did some benchmarking of the speed of propagating nn.Linear maps.
Before starting the clock, I create K linear maps of size MxM, and set some random parameters.
nodes = {}
for i=1,K do
local linearMap = nn.Linear(M,M)
if use_cuda then
linearMap = linearMap:cuda()
end
local par = linearMap:getParameters()
par:uniform(-1,1)
nodes[i] = linearMap
endThen I create for each replicate, I create some inputs and outputs, and compute a full round trip of forward and back-propagation. Every K replicates I stop to synchronize (i.e., flush all the queued up asynchronous GPU operations). I experimented with different values of K, but it didn’t seem to make a big difference at the computation loads I’m benchmarking.
for i=1,reps do
local x = Tensor(2,M):uniform()
local y = Tensor(2,M):uniform()
local j = (i-1) % K + 1
if j == 1 and use_cuda then
cutorch.synchronize()
end
local map = nodes[j]
map:zeroGradParameters()
map:forward(x)
map:backward(x,y)
endHere are the results:
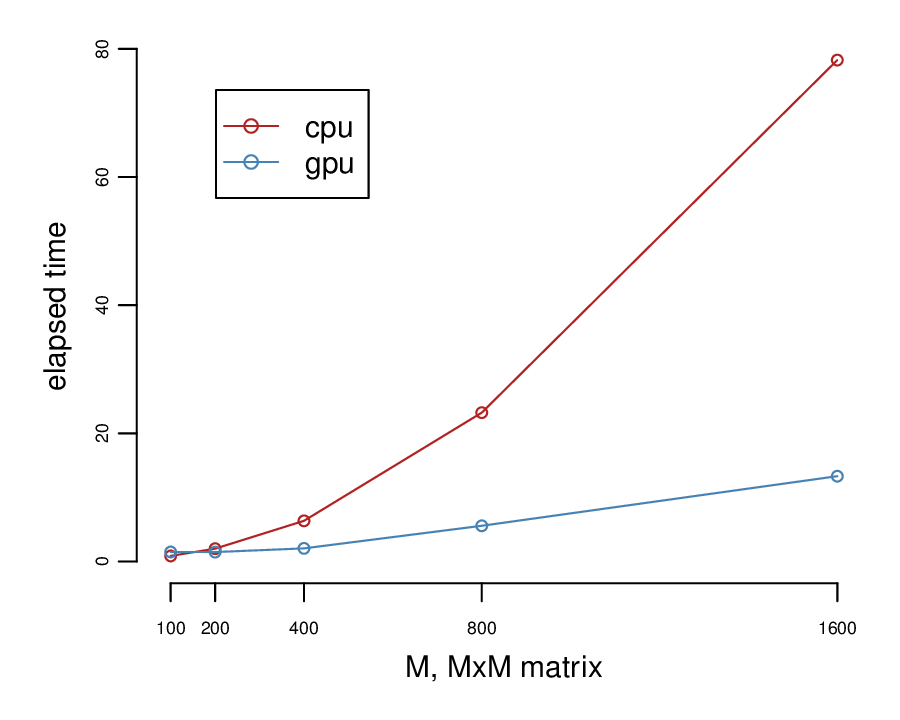
It’s worth noticing that for small matrices 200x200 or smaller it’s not worth using a GPU.